개요
- 개념
- 이점
- 사용사례
- 구조
- 사용
개념
Apache Kafka는 실시간으로 스트리밍 데이터를 수집하고 처리하는 데 최적화된 분산 데이터 스토어입니다. 스트리밍 데이터는 수천 개의 데이터 원본에서 연속적으로 생성되는 데이터로, 보통 데이터 레코드를 동시에 전송합니다. 스트리밍 플랫폼은 이러한 지속적인 데이터 유입을 처리하고 데이터를 순차적이고 점진적으로 처리해야 합니다.
Kafka는 사용자에게 세 가지 주요 기능을 제공합니다.
- 레코드 스트림 게시 및 구독
- 레코드가 생성된 순서대로 레코드 스트림을 효과적으로 저장
- 레코드 스트림을 실시간 처리
Kafka는 데이터 스트림에 적응하는 실시간 스트리밍 데이터 파이프라인과 애플리케이션을 구축하는 데 주로 사용됩니다. 메시징, 스토리지, 스트림 처리를 결합해 과거 및 실시간 데이터 모두의 저장 및 분석을 허용합니다.
- AWS kafka 설명
이점
- 확장성
Kafka의 파티셔닝된 로그 모델을 사용하면 데이터를 여러 서버에 분산할 수 있으므로 단일 서버에 담을 수 있는 수준 이상으로 데이터를 확장할 수 있습니다.
- 신속함
Kafka는 데이터 스트림을 분리하므로 지연 시간이 매우 짧아 속도가 극도로 빠릅니다.
- 내구성
파티션은 여러 서버에 분산되어 복제되며 데이터는 모두 디스크에 기록됩니다. 이렇게 하면 서버 장애로부터 데이터를 보호할 수 있어 데이터의 내결함성과 내구성을 높일 수 있습니다.
사용 사례
링크드인 - 링크드인에서 실시간 데이터를 처리하기 힘들어짐에 따라 kafka의 개발을 시작
- 적용 전
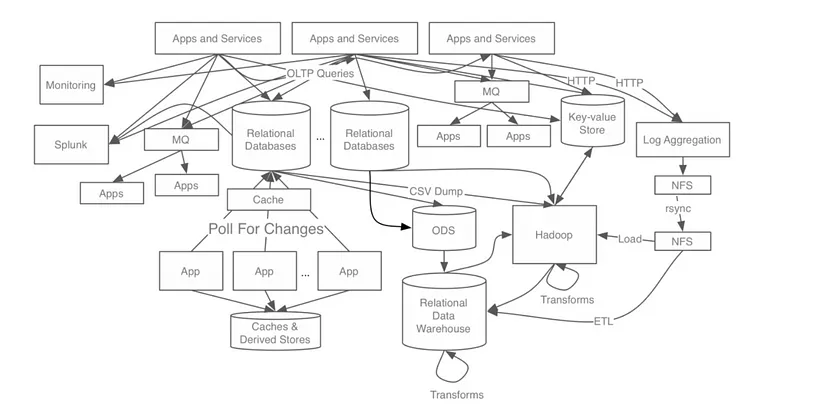
- 적용 후
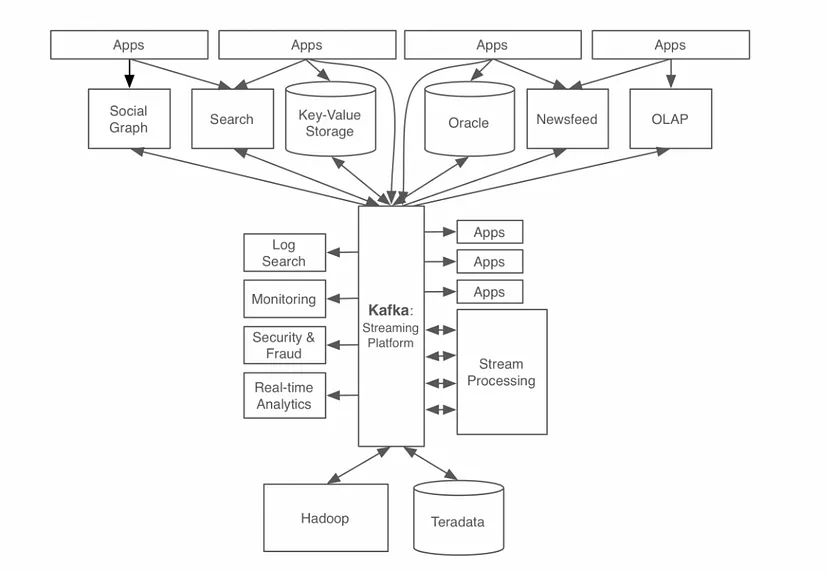
장점: 데이터의 흐름을 중앙 집중형으로 가져갈 수 있었다
구조
게시 - 구독

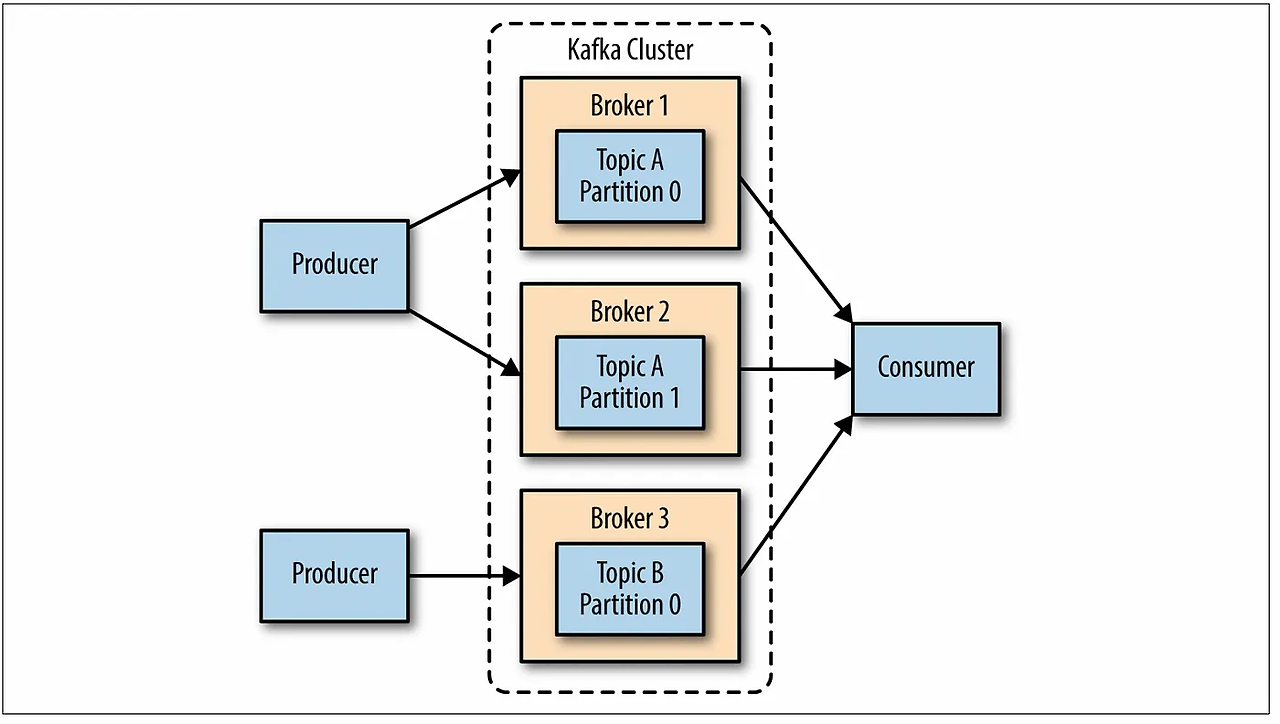
Producer: 이벤트 또는 데이터를 push 형식으로 저장해줌
Broker: 이벤트 또는 데이터를 queue 형식으로 저장함으로써, 지정된 시간 동안 데이터의 영속성 보장
consumer: pull 방식으로 Broker에 저장된 이벤트 또는 데이터를 가져옴
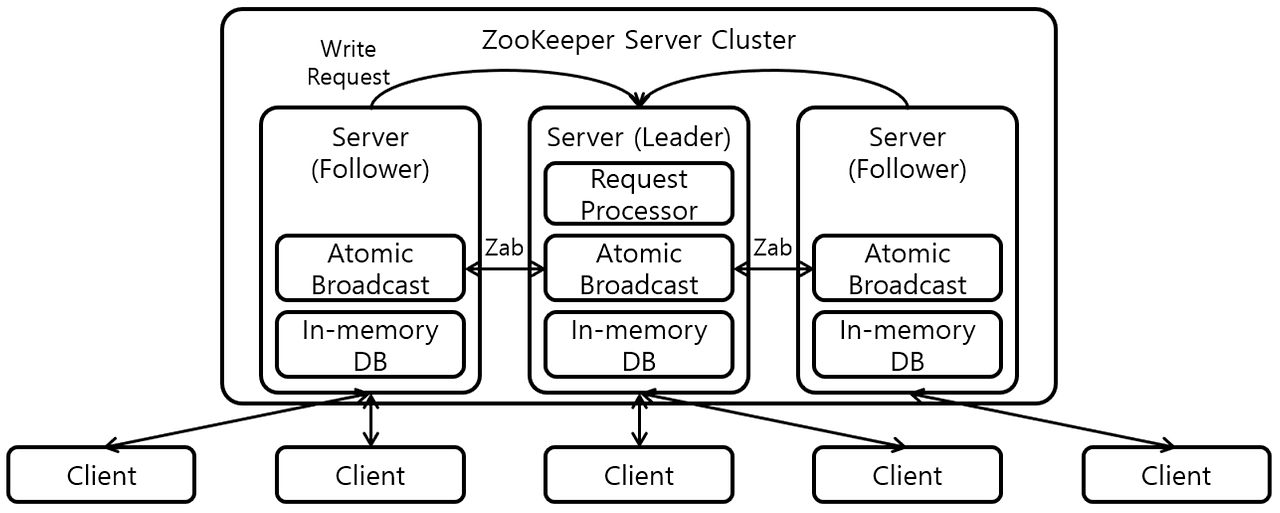
Zookeeper And Broker
zookeeper: Broker 상태를 확인해주고, 클러스터링 가능하게 해주는 서비스
- Leader: 데이터 읽고, 쓰기가 실행되는 환경
- Follower: Leader로부터 일정한 시간 간격으로 데이터를 가져와서 저장(Leader에게 이상이 있는 경우 Leader로 변경)
Topic: 여러 개의 Partition으로 이루어질 수 있다.
Partition: 데이터를 저장하고 곳으로 consumer가 데이터를 읽을때마다 offset으로 consumer가 읽은 데이터를 저장한다.
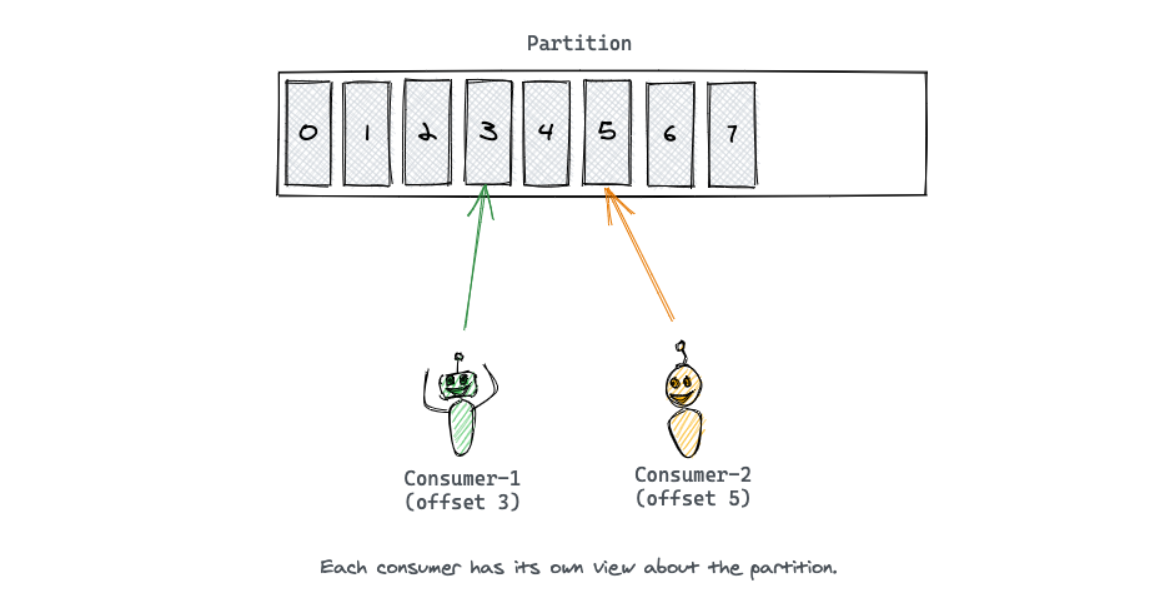
- Partition은 여러 서버에 존재할 수 있는데 이 때문에 높은 확장성을 보장 받을 수 있다.
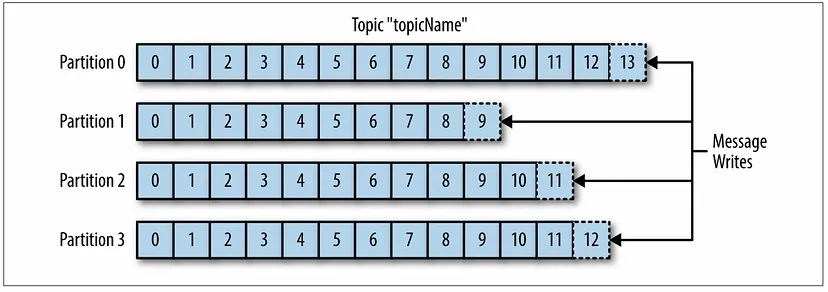
Producer and Consumer
Producer는 새로운 메시지를 특정 토픽에 생성하는데, 이 때 Producer는기본적으로 메시지가 어떤 파티션에 기록하는지는 관여하지 않는다.
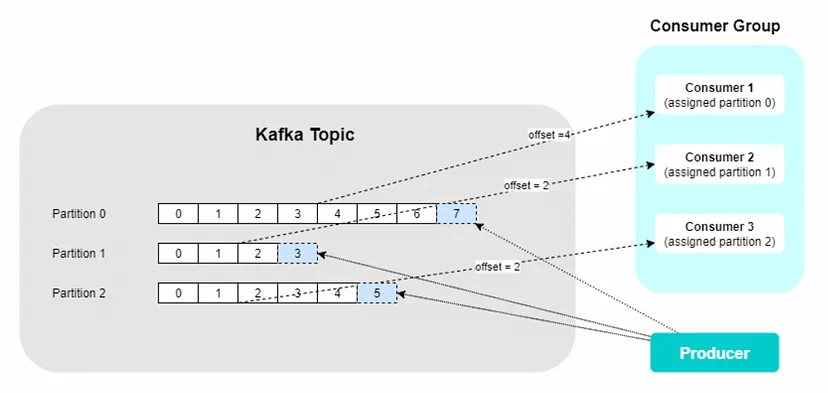
Consumer는 하나 이상의 토픽을 구독하면서 메시지가 생성된 순서로 읽는다.
Offset의 종류는 Commit Offset 과 Current Offset 이 있는데 Commit Offset 은 컨슈머로부터 ‘여기까지의 Offset은 처리했다’ 는 것을 확인하는 Offset이다.
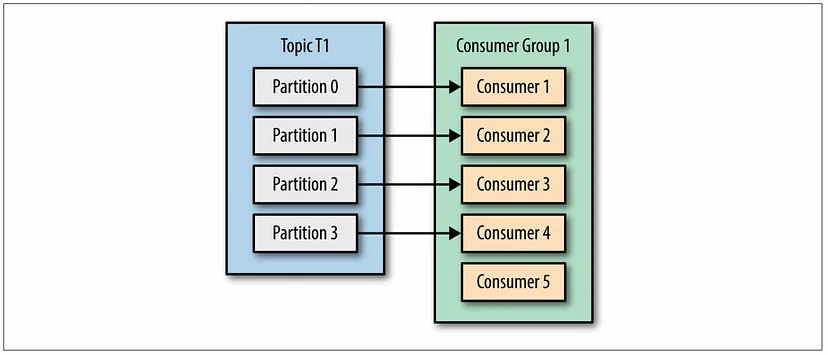
- Consumer 그룹에 Consumer가 많다고 데이터 소비량이 많아지지 않는다.
- 항상 partition의 개수와 동일하게 소모된다.
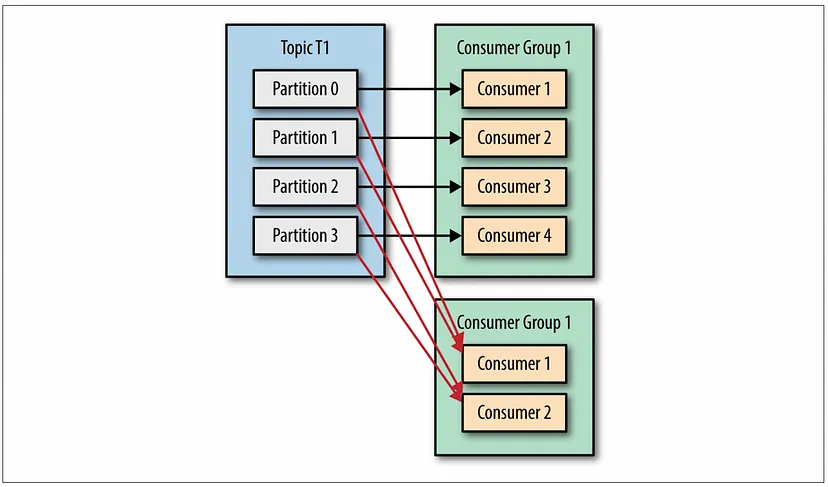
- 여러 consumer 그룹이 동일한 partition에 붙어 데이터를 읽어올 수 있다.
사용
Docker Compose로 KAFKA 설치
❗아래 Docker Compose는 테스트 용으로 운영 환경은 다른 설정이 필요합니다
version: '3.8'
services:
zookeeper:
image: wurstmeister/zookeeper:latest
ulimits:
nofile:
soft: 65536
hard: 65536
container_name: zookeeper
ports:
- "2181:2181"
kafka:
image: wurstmeister/kafka:latest
container_name: kafka
ports:
- "9092:9092"
environment:
KAFKA_ADVERTISED_HOST_NAME: 127.0.0.1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
volumes:
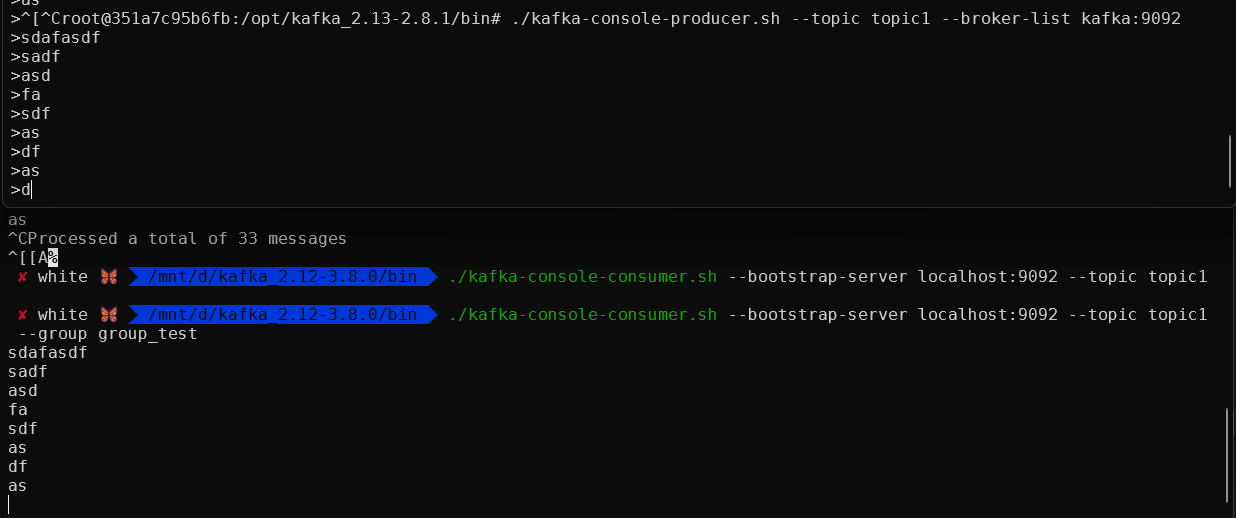
- /var/run/docker.sock:/var/run/docker.sock1-1) 생성된 container에 접속하여 topic을 생성합니다.
kafka-topics.sh --create --topic topic1 --bootstrap-server localhost:9092 --replication-factor 1 --partitions 31-2) Producer를 생성해줍니다.
./kafka-console-producer.sh --topic topic1 --broker-list kafka:90921-3) Consumer를 생성합니다.
❗여기서 consumer를 그룹으로 설정할 수 있습니다
cd /opt/kafka_2.13-2.8.1/bin/
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic1
--group group_test- 결과
Spring Boot
아래 내용을 Spring Boot에 추가합니다
@RequiredArgsConstructor
@RestController
@RequestMapping("messages")
public class MessageController {
@Autowired
private KafkaProducer kafkaProducer;
@PostMapping
public void sendMessage(@RequestBody String message) {
kafkaProducer.sendMessage("topic1", message);
}
}@Slf4j
@Component
public class KafkaConsumer {
@KafkaListener(group = "group_test", topics = "topic1")
public void consume(String message) {
log.info("Received message: {}", message);
// 메시지 처리 로직을 작성합니다.
}
}@Slf4j
@RequiredArgsConstructor
@Component
public class KafkaProducer {
private final KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String topic, String message) {
kafkaTemplate.send(topic, message);
log.info("Message sent: {}", message);
}
}application.properties
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.listener.type=batch
spring.kafka.consumer.group-id=group_test # 그룹 ID로 변경
spring.kafka.consumer.auto-offset-reset=earliest
spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
spring.kafka.producer.topic = topic1 # 원하는 토픽명으로 변경
spring.kafka.producer.bootstrap-servers=localhost:9094- 결과
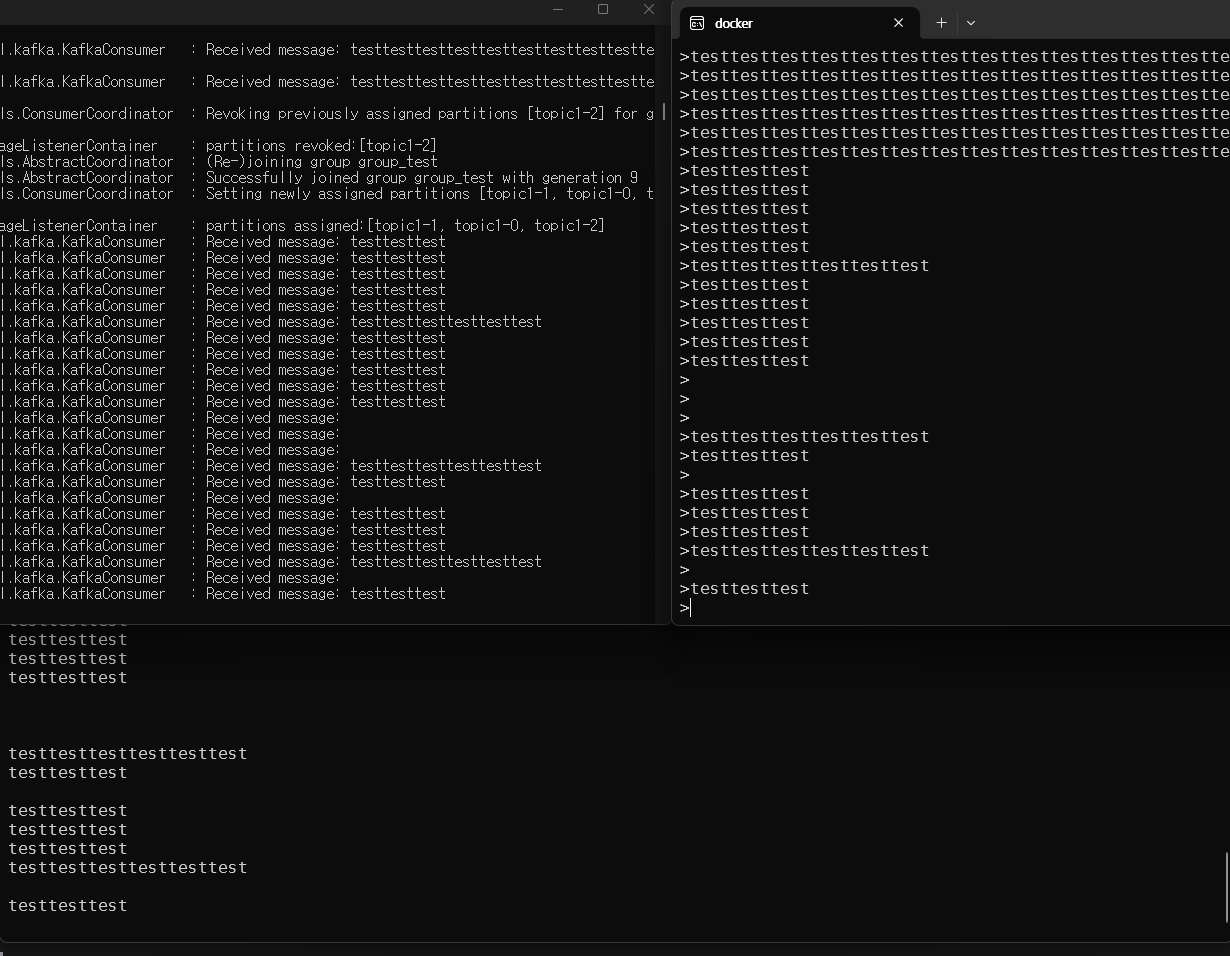
참조:
'BACK END' 카테고리의 다른 글
| No String-argument constructor/factory method to deserialize from String value (0) | 2024.11.29 |
|---|---|
| Redis 설정 및 사용법 (2) | 2024.10.29 |